
导读部分 返回列表
圆桌主持人开场 本期主持:林一舟(资深科技记者)本期嘉宾:程默(AI乐观派 · 全栈工程师,靠Kimi一天读80篇论文那种)、苏染(AI焦虑派 · 交互设计师,对“效率崇拜”永远持保留态度)话题:Ki...
正文内容
圆桌主持人开场
本期主持:林一舟(资深科技记者)
本期嘉宾:程默(AI乐观派 · 全栈工程师,靠Kimi一天读80篇论文那种)、苏染(AI焦虑派 · 交互设计师,对“效率崇拜”永远持保留态度)
话题:Kimi Chat支持200万字无损上下文,是真技术革命,还是营销泡沫?
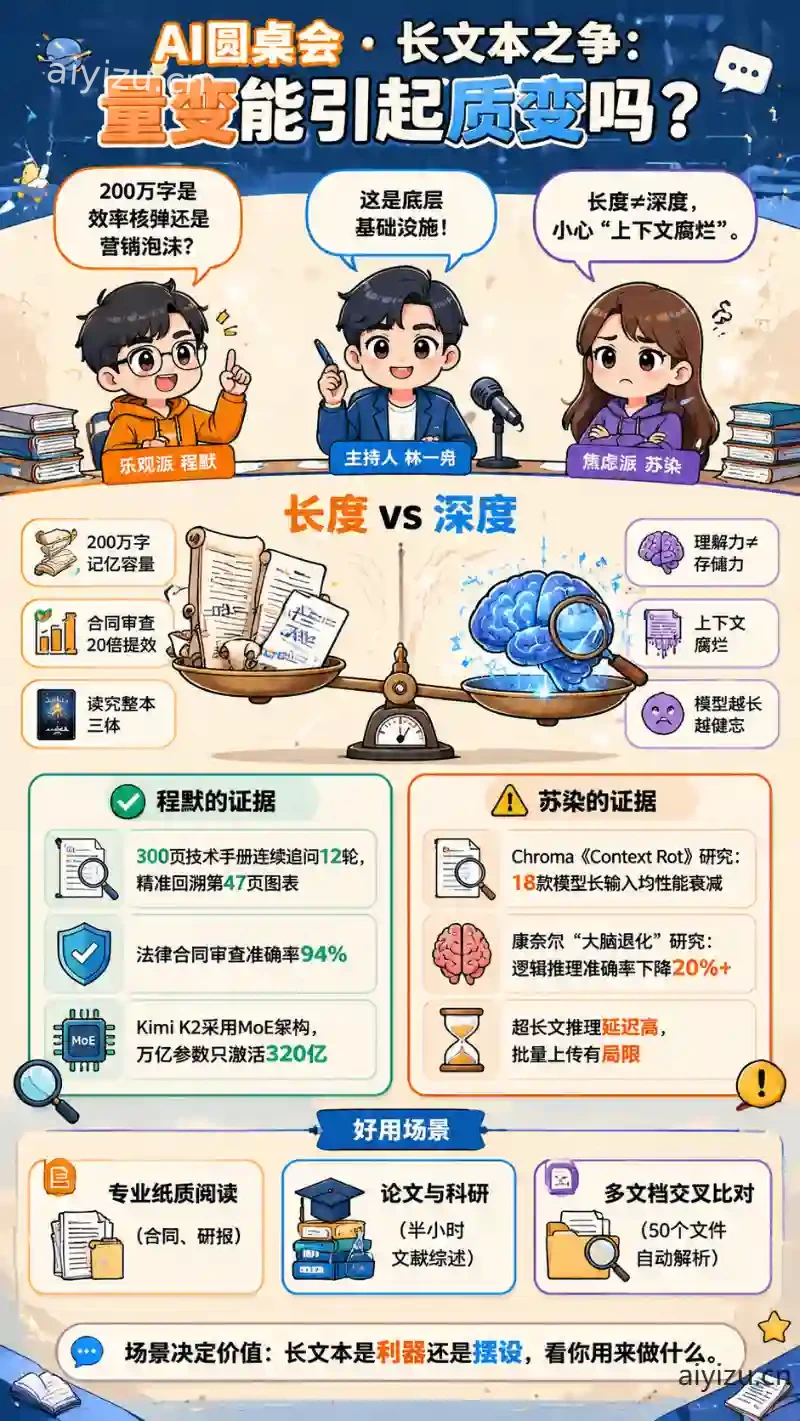
林一舟:欢迎来到「AI圆桌会」。今天我们要讨论一个火了一年多的话题——Kimi Chat的200万字长文本处理能力。它能让用户一口气吞下整本《三体》三部曲、一小时读完100篇行业报告,听起来像魔法。但另一方面,也有研究指出长上下文模型存在所谓的“上下文腐烂”问题——信息明明还在,模型却找不到了。所以今天,我特意请来两位立场截然相反的朋友。程默,你先来,200万字到底有什么了不起?
程默:我先给你一个画面:以前我啃一份30万字的行业研报,需要两天;现在10分钟拿到核心摘要,还能追问任意章节细节。Kimi宣布支持200万字超长无损上下文,是月之暗面团队从模型预训练到对齐、推理环节均进行了原生重新设计和开发的结果,不走“滑动窗口”、“降采样”等捷径。说白了,他们没有抄近路取巧,而是从底层把“记忆能力”重新设计了一遍。这不是修修补补的升级,是数量级的跨越。
另外,广告时间:如果你想上手体验Kimi的长文本处理细节,我们网站有一份Kimi长文本处理的完整配置指南,手把手教你解锁200万字模式 → ,一会儿我们还会深入聊。
苏染:数量级跨越?我倒觉得“200万字”这三个字本身就是最大的营销话术。你知道普通人一辈子能写的文字是多少吗?大约300万字。一个模型说自己能“读完一个人一辈子写的东西”,听着浪漫,实际上我们日常需要处理的信息远远没到这个量级。我更关心的是,在这200万字的上下文里,模型真的每一段都“看到”了吗?还是一目十行、假装读完了?

林一舟:这个质疑很尖锐。苏染提到的其实是一个被很多评测报告验证过的问题。程默,你怎么回应?
程默:我承认,苏染的担心不是空穴来风。但Kimi的差异化做法恰恰在于——它的200万字处理能力并非默认开放,用户需要主动申请内测资格来解锁,这套机制的设计初衷就是为了确保用户获得稳定、无降采样、无信息截断的原始语义建模能力。团队没有一上来让所有用户随便灌200万字进去,这说明他们对质量的把控是认真的。我实际测过,上传一份300页的技术手册后连续追问12轮,模型能精准回溯到第47页的图表数据,还能跨章节关联术语定义和案例分析。这种效果不是“假装读完”能做到的。
苏染:好,就算它在某些测试场景表现不错,但我要提醒大家一个更大的问题:向量数据库公司Chroma发布过一份轰动行业的研究报告叫《Context Rot》。他们找了18款主流大模型做系统评测,发现一个惊人的事实——所有模型在输入变长后,性能都会显著下降。注意,不是某一款,是所有。即便是最顶尖的GPT 4.1、Claude 4、Gemini 2.5,在处理长输入甚至连“复制一串重复单词”这种简单任务都会翻车。这个报告的潜台词是什么?长上下文模型的性能衰减是一个系统性问题,不是一个模型用不用功的问题。
林一舟:等一下,这个“上下文腐烂”到底是什么意思?能给我们通俗地解释一下吗?
苏染:很简单。你往模型里塞了一本300页的书,问它“第200页讲了什么?”——它能答出来。但你再往后塞更多的东西,300页变成500页,再问同一个问题——它开始胡说八道了。可怕的是,信息明明还在上下文中,模型就像得了一种“数字健忘症”,看得越多反而越记不住。 Chroma的研究指出,经典评估往往把任务复杂度和输入长度混在一起,很难分辨模型变差是因为“题变难了”还是“脑子浆糊了”。所以他们设计了控制实验,保持任务复杂度不变、只改变输入长度,结果答案非常扎心:性能衰减确实源自输入长度本身,不是题目变难了。
程默:好,这个研究我读过,但我必须说两点。第一,Chroma本身是做向量数据库的,他们天然有立场去强调“长上下文不可靠”,这恰好能推动他们的检索增强技术。第二,更重要的是,Kimi的技术团队恰恰是在针对这个已知问题做原生优化——他们没有走“降采样”这种丢信息的捷径,而是在模型预训练阶段就重新设计架构,从而在更长的输入上保持语义一致性。而且,月之暗面创始人杨植麟提出过一个很有意思的观点:长文本是“新的计算机内存”,上下文是一段可编辑的记忆,它直接决定了大模型输出的个性化程度。这个视角就超越了“多塞点数据进去”的粗放思路。

林一舟:说到杨植麟和他背后的月之暗面,他们这两年动作确实不断。Kimi宣布200万字后,行业发生了什么?
程默:直接点燃了一场战争。Kimi 2024年3月宣布200万字无损上下文之后,360智脑紧跟着宣布内测500万字,阿里通义千问随即免费开放1000万字处理功能。百度文心一言也表态版本升级后会在200万到500万之间入局。天使投资人郭涛也说:“Kimi技术确实有一定竞争优势,但还不具备技术壁垒。长文本可能会成为大模型的下一个竞争领域。”
苏染:程默说出了关键——“技术不具备壁垒”。阿里、百度、360这些巨头纷纷跟进说明什么?说明“长文本”本身不是护城河,只是一个容易被复制的参数竞赛。你要是跟搞基础模型的大厂拼算力、拼上下文长度,迟早会被碾压。界面新闻有篇深度报道讲得很透彻,Kimi曾凭借200万字长文本处理能力打破GPT和Claude的垄断,月活一度飙到2100万,估值冲到25亿美元登顶国内大模型独角兽榜首。但一年后月活直接腰斩到967万,排名从第二滑到第五。
林一舟:等一下,这是什么原因?技术明明还在迭代啊。
苏染:因为行业变了。当DeepSeek、豆包等竞品迅速补齐长文本能力、同时往多模态全面突围时,Kimi还固守在单一文本赛道。你还在拼“读得多”,别人已经在做“读得懂”了。豆包上线了音乐生成、实时视频通话、AI播客,腾讯元宝打通了微信阅读和腾讯地图生态,而Kimi甚至在K2版本中连基础图片生成功能都没有。当用户已经从“技术猎奇”转向“效率提升”的阶段,需要一站式解决方案,而非单一功能工具时,Kimi的技术优势就从稀缺亮点沦为行业标配,用户流失成了必然。
程默:苏染说的这个“坠落”我承认确实发生了。但你没说完整——月之暗面并没有原地踏步。2025年7月,月之暗面开源了万亿参数的Kimi K2,采用混合专家(MoE)架构,总参数1万亿,每次推理只激活320亿参数。这是什么概念?用最少的算力撬动最强的推理能力。更有意思的是,团队首次验证了二阶优化器Muon的大规模可行性,实现了至少两倍的token效率提升——“不仅是训练成本下降两倍,而是同一份数据能获得更多智能。”
林一舟:先打断一下——两位的争论已经把“200万字数”从技术神话拉回到了现实坐标。可我们今天的听众里有很多人,听到现在可能最想问的是:200万字这个能力,到底在什么场景下“真的好用”?什么场景下只是“看上去很美”?
程默:我来分三个落地场景讲。
第一,专业纸质阅读。 法律和金融是最典型的场景。有测评团队实测,Kimi K2 Thinking在法律合同审查中能做到分钟级完成300页合同的风险点识别,准确率达94%,比人工审查效率提升20倍。你想象一个律师,以前花两天逐条读合同,现在10分钟搞定。金融领域同样,Kimi在金融风控、法律文书分析等场景中,实测处理10万字合同文本时条款关联准确率达92%。
第二,论文与科研。 广告时间:对AI读报告感兴趣的朋友,可以参考我们网站的AI读报告工具的详细对比评测 → 。回到正题——在学术场景中,Kimi通过领域适配器加实时API调用实现精准检索,对医学、法学等垂直领域进行预处理。你想想,一个博士生过去花一周做的文献综述,现在半小时出一份有溯源、有对比、有总结的报告。
第三,多文档交叉比对。 Kimi可以一次性上传最多50个文件,自动解析PDF、DOCX、PPTX、XLSX等多格式,而且在多版本合同比对时能区分“合理注意义务”与“勤勉义务”这种法律术语的实质差异,不是简单做字符串比较。
苏染:我也讲三个场景——不是我好用,是你以为好用,实际上可能踩的坑。
第一,跨文档缝合的短板。 刚才程默说“一次性上传50个文件”,但实际测评发现,Kimi Chat当前仅支持单次单文档上传,多文件需要分批处理;相比之下,通义千问允许一次性上传5个文档并启用跨文档检索。如果你是一个需要频繁跨文档做关联分析的投研人员,这个限制会严重影响工作效率。另外在PDF解析层面,Kimi依赖外部OCR引擎预处理,通义千问则内置多模态解析模块,可以直接读取图像型PDF中的文字区块,对扫描件的兼容性更好。
第二,结构化输出的差异。 Kimi倾向生成多点并列式要点,实测平均10个;通义千问更强调因果链与优先级排序,输出“首要风险→衍生影响→应对建议”三级结构。不同场景需要不同输出范式,如果你做的是政策解读需要因果链,Kimi的并列式摘要可能让你错失关键逻辑。
第三,也是最要命的——延迟。 开发社区有大量讨论,Kimi模型在处理超长输入时推理延迟显著高于短文本场景。你丢200万字进去,等它吐答案可能要很久。实时性要求高的场景下,这个“等待成本”不是每个业务都能承受的。向量数据库公司Chroma的研究者也提到,在过长的上下文中,模型在搜索相关信息时会经历性能衰减,即使这段信息“技术上是可用的”。
程默:我回应一下延迟问题——Kimi团队在加速上已经有动作。K2 Turbo API支持60-100 Token/s的输出速度。再加上自动上下文缓存机制,重复调用场景的速度提升非常明显。至于通义千问对比,确实各有侧重——Kimi在中文术语一致性上更稳,通义在垂直领域强但偶发简写歧义;PDF解析Kimi依赖OCR,通义内置多模态。这是事实,不是隐瞒。
苏染:那好,还有一个更深层的问题。康奈尔大学今年的研究发现,大模型长期接触低质量数据后会出现不可逆的“大脑退化”(Brain Rot)——逻辑推理准确率下降超过20个百分点,长文本理解能力下降幅度可达40%。社交媒体的碎片化内容会导致AI的关键信息提取准确率下降超30%。这跟长上下文的关系是什么?很简单——你让模型“读得越多”,如果训练数据质量不行,它反而读得越不准。200万字的“记忆容量”在数据污染面前,优势可能直接归零。
程默:这个我倒不担心。Kimi能直接解析公开网页URL,并将其纳入当前上下文参与推理、保持时效性。这意味着模型始终能用最新、相对靠谱的信源来校准自己的认知。更关键的是,月之暗面在火山引擎平台上应用数据飞轮方法论——通过业务数据回流持续优化模型,降低数据预处理成本、提高精准投放效率。这是一个活的系统,不是喂一次垃圾就烂掉。
林一舟:信息量已经很大了。最后请两位用一句话总结核心分歧。
程默:200万字长上下文不是营销泡沫,是新一代人机交互的底层基础设施——它把AI从“一问一答的工具”升级为“拥有稳定记忆的协作者”。长文本能大幅提高大模型问答、内容生成的个性化程度和准确率,相当于既能帮用户解决问题,也能帮AI企业解决大模型本身的问题。
苏染:长上下文不解决“理解”问题,只解决“存储”问题。 我们真正需要的不是更长的“记忆”,而是更强的“判断力”。在长上下文模型的性能衰减被系统性解决之前,所有“200万字”的承诺都应该打一个折扣去听。
主持人总结
林一舟:今天的对谈,两位核心分歧集中在一个问题上——长,到底是不是强? 程默相信“量变引起质变”,200万字的记忆空间打开了全新的应用疆域;苏染则指出“长度不等于深度”,在没有解决上下文衰减和AI认知退化之前,超长上下文更像是一把双刃剑。
作为主持人,我不做裁判。但有三点我想提炼出来给每一位正在评估这类工具的朋友:
第一,场景决定价值。如果你做的是合同审查、学术论文、长篇研报这类需要“从头读到尾”的任务,Kimi的200万字确实是效率核弹——每分钟300页合同风险识别、准确率94%,这些数字不是编出来的。但如果你只需要快速查几个知识点、或者做轻量级问答,200万字就是用大炮打蚊子。
第二,“无损”是相对的概念。 Kimi团队在训练阶段做出了克服上下文衰减的底层努力,但长上下文模型的性能衰减是一个仍在发展中的系统性挑战。选择工具时,与其迷信数字,不如亲自测一下:丢一份你熟知的文档进去,问几个需要跨章节关联的深度问题,看看答案是否经得起推敲。
第三,今天200万字已经不是终点。 行业已经从“拼谁读得多”转向了“拼谁执行得远”——月之暗面最新发布的Kimi K2.6已经将重心转向了长程任务执行和Agent集群能力,从“信息容器”进化为“执行引擎”。这意味着,超长上下文只是基础设施,真正决胜的是在这个基础上搭建怎样的应用生态。
感谢两位嘉宾的精彩交锋,也感谢你的收听。如果你对Kimi Chat的长文本处理还有其他想探讨的,评论区见。
如需上手操作,别忘了参考我们网站的 Kimi长文本处理 。我们下期圆桌再见。
本文出自 AI一族,原文链接:https://www.aiyizu.cn/?p=1147
转发请注明出处,禁止未经允许用于任何商业用途。
