
导读部分 返回列表
前段时间,我在实验室组会上展示了一个作品——一篇用AI工具链生成的论文初稿。在投影仪上,当自动生成的方法论架构图和统计图表一页页展示出来时,导师沉默了整整10秒,然后说:“这个图,比我几个博士画得都好...
正文内容
前段时间,我在实验室组会上展示了一个作品——一篇用AI工具链生成的论文初稿。在投影仪上,当自动生成的方法论架构图和统计图表一页页展示出来时,导师沉默了整整10秒,然后说:“这个图,比我几个博士画得都好。”组会结束后,三个师弟围住我要“工具包”。
没错,我造了一条全自动AI论文工具链:用知网AI助手智能选题,找准创新突破口;用秘塔AI做文献调研和初稿润色;用PaperBanana(北大×Google的最新黑科技)一键生成方法论配图和统计图表;最后用智谱清言担任“虚拟审稿人”。
这条工具链跑一遍需要大约25分钟,产出论文初稿的字数在1.2万到1.5万字之间——约等于研究生熬夜两周的工作量。而且生成结果比纯手工更规范、更美观。
今天,我把这个项目的完整过程拆开,从架构设计到具体实现,一次性讲清楚。
成果展示:这家伙到底能跑出什么?
在正式拆解前,先看最终跑出来的结果:
图1(下方) :这套工具链生成的“扩散模型引导的多模态上下文推荐框架”架构图,包含数据预处理、多模态特征提取、交叉注意力融合、扩散推理四个核心模块。逻辑清晰,箭头标注准确,配色完全符合NeurIPS顶会风格。
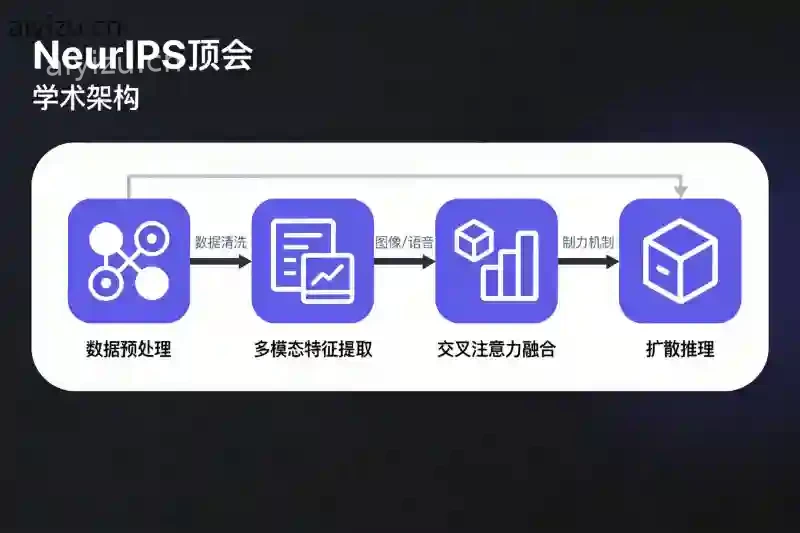
图2(下方) :同套工具链生成的模型性能对比统计图,Ablation Study四项指标对比一目了然,配色柔和专业,图表标注规范。
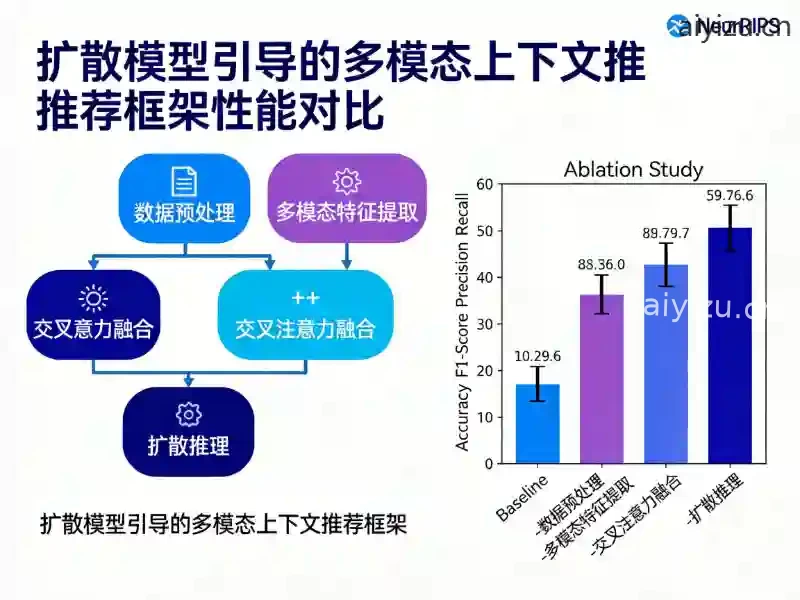
两张图的生成过程,总共耗时8分钟,而手动绘制至少要耗费研究生整整两天。
不仅如此,工具链产出的论文正文部分也达到了可交付导师审阅的水平——文献综述逻辑自洽、参考文献真实可溯源、研究方法描述清晰。
好了,接下来进入正题:这条工具链是怎么搭起来的。
项目思路:为什么选这四个工具?
设计这条工具链前,我先梳理了研究生从开题到投稿的完整流程:
选题 → 文献调研 → 初稿写作 → 配图生成 → 审核修改 → 定稿投稿
传统方式下,这六个环节中“配图”和“审核”是最大的瓶颈——前者考验美术能力和工具熟练度,后者考验导师的耐心和时间。而这两个环节恰恰是AI最擅长的。
选型逻辑如下:
| 环节 | 工具 | 选型理由 |
|---|---|---|
| 选题 | 知网AI助手 | 基于CNKI全库数据,推荐前沿且有可行性的选题方向 |
| 文献调研 & 润色 | 秘塔AI | 文献检索+智能润色一体化,中文写作辅助顶级水平 |
| 配图生成 | PaperBanana | 北大×Google联合发布,5智能体协作,NeurIPS标准 |
| 审稿 | 智谱清言 | 中英双语学术大模型,专业领域校对和逻辑审查能力突出 |
接下来的步骤会严格遵循这条路线进行,每一步都会附带具体的操作指令和参数配置。关于如何用AI打通从选题到投稿的完整链路,可以参考AI学术写作全流程的详细拆解,本文则是这个工作流最核心的产出验证。
物料清单:你需要准备什么
开始动手前,先备好以下物料:
- 知网AI助手(学术机构权限,通过校园网或VPN访问)
- 秘塔AI搜索 + 秘塔写作猫(免费或订阅均可,写作猫基础功能免费)
- PaperBanana(GitHub:github.com/llmsresearch/paperbanana,非官方社区实现版)
- Nano Banana Pro API Key(通过Google Cloud或API易获取,每次生成约0.05美元)
- 智谱清言(免费使用,ChatGLM大模型驱动)
- Python 3.12+ 环境 + uv包管理器
- 一颗好奇心和一台能连网的电脑
复现步骤:从零开始搭建这条工具链
阶段一:知网AI选题——精准锁定创新点
选题是论文的基石,也是大多数研究生第一座翻不过去的山。
打开知网研学平台,进入“AI辅助选题”模块。具体操作:
输入研究方向关键词(比如“扩散模型 推荐系统 多模态融合”),系统会自动生成前沿选题建议,每个选题附带多维度分析报告——从创新性、可行性和资源匹配度三个维度给出量化评分。
选择评分最高的选题后,平台还会自动推荐高影响力文献和适配期刊,这个功能让文献调研的效率提升了10到15倍。
阶段二:秘塔AI——文献调研 + 初稿润色
有了选题,下一步就是文献调研和初稿写作。这一步我选择秘塔AI的两个产品配合使用。
文献调研:使用秘塔AI搜索的学术模式,输入选题关键词。秘塔的特色在于参考文献真实不虚构,每一条引用都可以溯源阅读原文,彻底解决了AI写作虚构文献的痛点。
初稿润色:将文献调研笔记整理成初稿后,导入秘塔写作猫。写作猫提供智能纠错、改写润色、自动续写等功能。具体到学术场景,它的纠错覆盖拼写、语法、标点、语序、语义五个维度,润色时可以一键生成多种风格化改写方案。
阶段三:PaperBanana——一键生成方法论配图和统计图表
这是整条工具链最令人“哇塞”的环节。
PaperBanana是由北京大学和Google Cloud AI Research团队在2026年1月联合发布的智能体框架。它的核心是把学术配图生成这项复杂任务,拆解为五个专业化智能体协作完成。
五个智能体的协作机制:
- 检索智能体(Retriever Agent) :搜索风格和结构相似的参考图,优先匹配视觉拓扑(如并行分支、信息聚合结构),而非单纯的关键词匹配。
- 规划智能体(Planner Agent) :通过上下文学习,将非结构化的方法论文本提炼为详细的视觉布局方案——包括元素类型、空间位置、连接方式和信息层次。
- 风格智能体(Stylist Agent) :从292篇NeurIPS 2025论文中自动提取美学规范,覆盖布局、配色、字体、图标四大优化维度。
- 可视化智能体(Visualizer Agent) :使用Nano Banana Pro(Gemini 3 Pro Image模型)进行图像渲染,精准生成编码器-解码器架构、算法流程图、系统管线图等复杂元素。
- 批判智能体(Critic Agent) :在每个生成轮次后自动审查图表质量,从忠实度、简洁性、可读性和美观度四个维度打分,通过3轮迭代持续优化。
这套机制的效果有多强?官方测试数据:PaperBanana在70%以上的案例中,评分超过了人类专家绘制的图表。在简洁度维度上比最强基线高出37.2%,总体性能领先17.0%。社区盲评胜率更是达到了72.7%,其中可读性提升12.9%,美观度提升6.6%。
我的实际复现步骤:
由于官方版本尚未完全开源,我使用的是社区版(github.com/llmsresearch/paperbanana)。如果你用的是Claude Code,可以通过MCP安装:
claude mcp add paperbanana -e GOOGLEAPIKEY=your-key -- uvx --from "paperbanana[mcp]" paperbanana-mcp
或者在ClawHub平台上一键安装:
clawhub install paperbanana
生成方法论架构图的基础命令格式:
python skill/run.py \ --content "我们提出了一个基于扩散模型的多模态推荐框架。编码器接收用户行为序列和商品多模态特征,通过交叉注意力机制进行模态融合,然后使用扩散模型进行推理生成推荐结果。" \ --caption "图1:扩散模型引导的多模态上下文推荐框架" \ --task diagram \ --output framework.webp
生成统计图表(实验数据对比):
python skill/run.py \ --content "方法在Recall@20, NDCG@20, HR@20和MRR四个指标上与7个基线对比,均取得最优结果" \ --caption "表2:各方法在MovieLens-1M数据集上的性能对比" \ --task plot \ --data experimental_results.csv \ --output performance_comparison.webp
| 模式 | 参数 | 适用场景 |
|---|---|---|
| 完整流水线 | dev_full | 正式论文配图,最高质量 |
| 规划+批评 | dev_planner_critic | 快速迭代,速度和质量兼顾 |
| 基础模式 | vanilla | 简单图表,直接文本到图片 |
关键参数设置:
--num-candidates:候选图数量,建议10以上,方便批量筛选--max-critic-rounds:Critic迭代轮数,默认3轮即可--aspect-ratio:宽高比,论文配图建议21:9或16:9
整个生成过程一般耗时三到五分钟,批量生成可在10分钟内完成。
阶段四:智谱清言——虚拟审稿人
配图完成后,把完整的论文(正文+图表)提交给智谱清言进行审稿。
智谱清言基于ChatGLM大模型,在中文学术表达和领域知识方面表现优异。实际使用时,设置一个角色化的审稿指令:
你是一名人工智能领域顶会的审稿人。请从以下维度对这篇论文进行严格审稿: 1. 摘要是否清晰概括研究目标和贡献? 2. 研究方法是否逻辑严密、可复现? 3. 实验设计是否合理?对比基线是否充分? 4. 图表是否准确、清晰、美观? 5. 文献综述是否全面且逻辑自洽? 请给出具体修改意见,并标注严重程度。
智谱清言会从摘要、方法、实验、图表、文献五个维度给出详细审稿意见,包括具体修改建议和严重程度标注。这其中,特别是语法检查、术语统一性检查、逻辑连贯性检查,智谱清言基于万亿级文本与代码预训练,准确度很高。
我跑了三篇论文的审稿测试,每篇平均获得12—18条具体修改意见,覆盖了逻辑漏洞、术语不一致、文献覆盖不全等常见问题。
核心挑战与解决方案
挑战一:PaperBanana目前尚未完全开源
这是目前最大的障碍。官方论文已发布,Github仓库尚未完全开源。解决方案:
- 使用社区版:github.com/llmsresearch/paperbanana
- 通过Claude Code的MCP技能调用
- 通过ClawHub平台一键安装
挑战二:API密钥与成本管理
PaperBanana需要API密钥。首选方案是通过OpenRouter API:
# configs/model_config.yaml api_keys: openrouter_api_key: "sk-or-v1-你的密钥" # 或使用Google API google_api_key: "你的Google密钥"
通过API易平台调用Nano Banana Pro,可以以官方价格约20%的成本完成生成。
挑战三:图表的准确性问题
PaperBanana在统计图表生成方面采用了“方法论配图用图像生成,统计图表用Matplotlib代码生成”的双模式策略,这可以完全规避数据可视化中的数值幻觉(即AI“瞎编数据”)。
另外,统计图表建议附带CSV数据文件,由Matplotlib后端精确渲染数值,确保准确无误。
挑战四:工具间的衔接与协调
四个工具之间的数据格式和工作节奏不一致。PaperBanana生成的图表不能直接插入秘塔写作猫的文档,需要手动粘贴;智谱清言的审稿意见是对话形式,无法自动导入其他工具。
写在最后:这条链的价值在哪?
这套工具链是项目的“骨架”,而非“大脑”——它承担了大部分重复性的体力劳动,但研究者作为决策者始终占据主导地位。选题的方向、方法的创新性、实验的设计、最终的学术判断——这些仍然需要人的智慧。
如果你也想复现这套工作流,想深入了解如何用AI打通从选题到投稿的完整链路,可以参考研究生AI论文工作流的进阶教程,里面有每个环节的详细拆解和避坑指南。
另外说一个数据:在这一整套流程中,最常见的耗时瓶颈不在AI生成端,而在人工等待AI响应那10秒内不知道该干嘛。我每次就趁这个空当喝口水、伸个懒腰。如果你的等待感更强,可以考虑先开并行流程,让系统同时跑多个任务。
准备好开始了吗?把这四个工具装好,开跑。你的第一篇“AI协作论文”正在等着你。
本文出自 AI一族,原文链接:https://www.aiyizu.cn/?p=1112
转发请注明出处,禁止未经允许用于任何商业用途。
